This lab is focused on taking our existing infrastructure and implementing some of the BGP Best Practices to secure the configuration on the router, as covered in the BGP BCP presentation earlier.
The lab work looks at 5 essential configuration features necessary to secure BGP operations on a router:
Limiting the maximum AS-PATH length for received prefixes
Protecting the EBGP Peerings from receiving more than the expected number of prefixes
Generalised TTL Security Mechanism - how to prevent remote attackers from disrupting EBGP sessions
Propagation of BGP Communities
Preventing the propagation of private AS numbers to the Internet
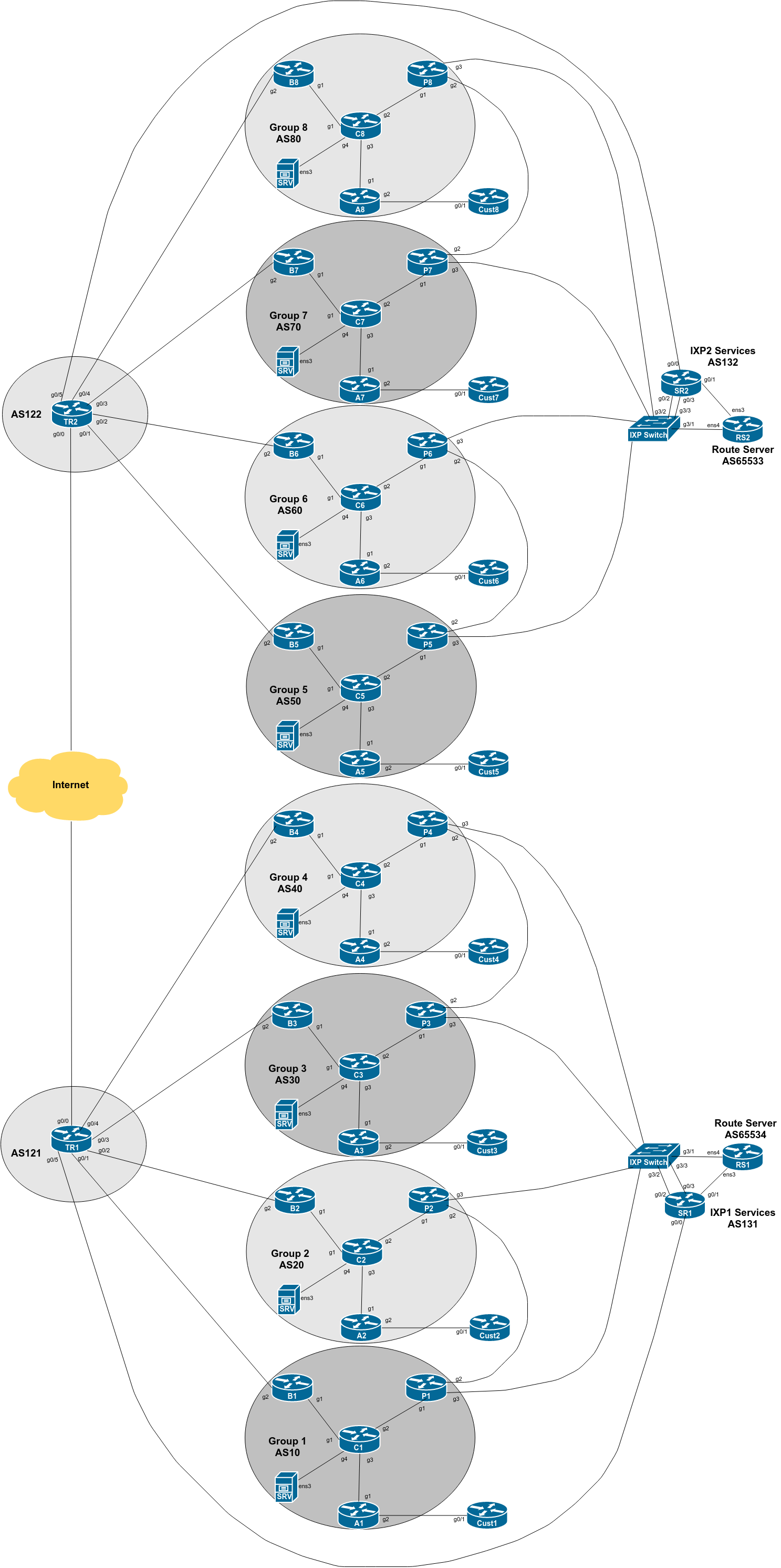
The diagram below is a reminder of the lab topology:
The first in the series of exercises to be looked at is limiting the AS PATH length received on prefixes received from other providers around the Internet. The Internet is not very “deep” in that the typical number of AS hops to get from any one operator to any other operator is around five.
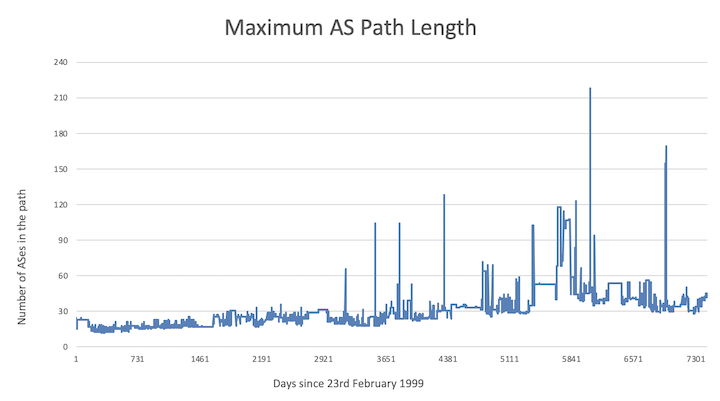
It is highly unusual in today’s highly interconnected network to see more than 10 or 15 consecutive (and different) AS numbers in any one path. However various researchers and observers of the global routing system have noted instances from time to time where some operators will announce prefixes with extraordinarily long AS PATHs, usually done by inserting dozens or even over one hundred of their own AS number when the prefix is announced. It is not entirely clear why this is being done, and most conclude that it is down to either operator error, operator ignorance, or a misunderstanding of what the AS-PATH attribute is actually used for.
Cisco IOS has a BGP generic configuration option called maxas-limit. What this does is drop any prefix with an AS-PATH attribute longer than the number of ASes listed in the command.
Each group connects to upstream transit provider, private peer, and public peers via the IXP. We are going to set the maxas-limit command on our Border and Peering routers. There is nothing to be gained by doing this on routers with only IBGP sessions, as we are implementing our BGP policy at the edge of the network, on the EBGP sessions (as discussed in the presentations).
To show you how it works, we will set the AS-PATH length limit to 5. Here is an example for the Border Router, peering with the upstream provider:
router bgp X0
bgp maxas-limit 5
!Don’t forget to implement this on the Peering Router as well.
Please note that a value of 5 is not suitable for an Internet connected router receiving the full BGP table and no default route - while the average AS-PATH length is 5 hops, the typical longest usable paths can be up to 15 AS hops. Most operators set the AS-PATH limit to 20 or thereabouts, as noted in the background above.
While you are doing this exercise, the lab instructors will start originating some prefixes from the two Transit providers - you will notice that these prefixes have a very long AS-PATH on them. Check what happens before you implement the above policy, and after you implement it.
Have a look at the router logs - do you see messages like this (taken from an earlier version of this lab):
%BGP-6-ASPATH: Long AS path 122 121 121 121 121 121 121 121 121 121 10 received from 100.122.1.0: BGP(0) Prefixes: 100.68.1.0/24Also set up the same configuration on your Peering Router, where you peer with your private peer and with the IXP Route Server. It might appear to be less likely that a directly connected peer will originate prefixes with a very long AS-PATH, but the unusual can happen, and it is always better to have consistent policies applied to all EBGP neighbours.
Note: Cisco IOS also has similar commands to limit the number of communities and extended communities attached to prefix announcements. Can you find them from the CLI?
Discuss amongst your group what you think might be the reasons for these unusually long AS-PATHs.
Here are some possibilities mentioned earlier:
operator error - what sort of errors could these be?
operator ignorance - what does the AS-PATH attribute do, and what is it used for?
software error - any examples?
Any others?
The figure below show the last 20 years of the maximum AS-PATH length observed in the global Internet from one vantage point in Japan.
The next protection and preventative measure we will look at is setting a limit on the maximum number of prefixes receivable from an EBGP peer. This activity is vitally important to help keep the routing system stable and deal with issues due to missing or erroneous filters applied to EBGP sessions.
For example, if two networks peer with each other, and exchange 10 prefixes they each originate, then they’d reasonably expect to receive no more than 10 prefixes from each other. If each operator was following best practices, they’d set up a strict prefix filter to only allow the specific filters they’d expect from their peer.
However, it isn’t always possible to set up strict filters, so another protective measure is required. This is usually the case where the network operator is receiving a large number of prefixes from another peer and all the customers of this peer as well. While they may be able to filter from the direct peer, it is harder to filter what the peer’s customers are sending as they don’t have that direct knowledge/relationship, and are not using the Internet Routing Registry (which was designed for this very purpose). This assumes and trusts that their peer will filter their customer and their own announcements according to best practices - but what happens if this filter breaks? A peering which might be exchanging 2000 IPv4 prefixes could end up exchanging the entire global IPv4 table instead, all of 810000 prefixes at time of writing these notes.
The classic well known example is of two upstream providers with an access provider as their customer. The access provider received full routes from both upstreams. A mis-configuration by the access provider on one of its upstream links during maintenance work resulted in the full routes from one upstream provider being sent to the other upstream provider. And because upstream provider policy is to give high preference to customer routes, they ended up giving high preference to the global routing table learned via their customer; higher preference than their own upstream links. Which resulted in their transit traffic going via their customer out to the other upstream. This caused a major outage for both upstream providers and for their mutual customer. And could have been easily prevented by proper prefix filter or, in the absence of that, at least implementing the maximum-prefix concept we are now about to configure.
We are now going to implement Cisco IOS maximum-prefix on all our EBGP sessions. The Cisco command has several options, as described in the presentation:
neighbor <x.x.x.x> maximum-prefix <max> [restart N] [<threshold>] [warning-only] The options are:
restart is an optional keyword which will restart the BGP session N minutes after being torn down. This is useful in the case where the EBGP session can be restored after waiting, just in case the prefix overflow was caused by a maintenance error on the peer network.
threshold is an optional parameter between 1 to 100, specifying the percentage of max that will cause a warning message to be generated. Default is 75%.
warning-only is an optional keyword which allows log messages to be generated but peering session will not be torn down - use this with care because if the log messages are not being monitored, the EBGP session could overflow resulting in an outcome similar to the scenario described earlier.
Determine how many prefixes you are currently receiving on all your EBGP sessions. Once you have done that, double the number, and use that for the appropriate EBGP session.
We suggest using 30 as the maximum-prefix as this will allow for future scenarios in this lab - do not make it bigger than 30 otherwise you may not see the effect of applying maximum-prefix to the BGP session when the instructors inject more prefixes into the network.
Here is an example for the Border Router, peering with the upstream provider:
router bgp X0
!
address-family ipv4
neighbor <ipv4-ptp> maximum-prefix 30
!
address-family ipv6
neighbor <ipv6-ptp> maximum-prefix 30
!To maintain consistency, do the same for the EBGP sessions on the Peering router. Your group is currently receiving 4 prefixes from the IX Route Server, and later in this particular lab you will receive another 3, so perhaps set the maximum-prefix threshold here to be 15.
You will only be getting one prefix from your private peer - setting maximum-prefix to 2 might be a bit strict, so perhaps set it to 5 instead, which will allow for the 75% threshold warning to notify you of problems first.
Once you have put the configuration in place, let the lab instructors know. They will now “accidentally” send a large number of prefixes on the EBGP session with your group’s border router. What happens now?
You should see that the BGP session will be disabled as soon as the maximum prefix threshold has been passed. Run the show ip bgp and show bgp ipv6 unicast commands. You should see something like this (for router B1 in an earlier version of this lab):
B1#sh ip bgp sum
Neighbor V AS MsgRcvd MsgSent TblVer InQ OutQ Up/Down State/PfxRcd
100.68.1.2 4 10 62 57 39 0 0 00:47:23 8
100.121.1.0 4 121 0 0 1 0 0 00:00:38 Idle (PfxCt)The PfxCt comment under the State/PfxRcd column shows that the maximum-prefixes allowed has been exceeded for this peering, and the router has disabled the BGP session.
Run the show log command and check what the router logs have recorded. You might see something like this:
%BGP-4-MAXPFX: Number of prefixes received from 100.121.1.0 (afi 0) reaches 19, max 25
%BGP-3-MAXPFXEXCEED: Number of prefixes received from 100.121.1.0 (afi 0): 26 exceeds limit 25
%BGP-5-NBR_RESET: Neighbor 100.121.1.0 reset (Peer over prefix limit)Note the first entry %BGP-4-MAXPFX is the router warning the operator that the 75% threshold has been reached. The second entry %BGP-3-MAXPFX-EXCEED warns that the limit has been exceeded. And the %BGP-5-NBR_RESET has reset the BGP session because of this.
Once the instructors are satisfied with the maximum-prefix demonstration, they will withdraw the extra prefixes they have introduced into the workshop lab network.
Notice that the Border router will not automatically restore the BGP session. You will need to do a manual hard reset of the BGP session before it is restored.
If you had set warning-only as an option, the EBGP sessions wouldn’t have been taken down - they’d have kept running, but kept sending warning messages while the BGP peering was receiving more prefixes than configured.
If you had set a restart time, then the border router would have tried to restart the peering session every period that you had set for the restart.
If there is time, experiment with these two options and see what happens to the EBGP sessions each time.
The next exercise is looking at a technique for protecting BGP sessions between routers from being attacked by a third party. This protection is in addition to using a password on the EBGP session, as we configured during the setup stages of this workshop.
An EBGP session between two directly connected peers means a TTL hop count of 1 is set on the originating router, with the destination router expecting the packet to arrive with TTL of 0. However, an attacker elsewhere on the Internet can also send a packet which will arrive with TTL of 0, and potential disrupt the BGP session between the two peers.
GTSM works by setting TTLs between EBGP speakers to be 255, as described in the BGP Best Practices presentation. This way, a third party can only be at least one more hop away; it cannot send a BGP packet with TTL which the local peer router would be able to use, because the TTL would be incorrect. If they tried to send a packet with TTL 255, and they were one hop beyond the source router, the packet would arrive on the destination router with a TTL of 253, two hops away, an incorrect value and therefore ignored. (In fact, the attacker would have to be on the same physical media used between the two peers meaning that, in the case of an IXP, they’d have to be on the IXP LAN itself - not entirely impossible!)
Some operators require GTSM on any EBGP session they set up - so the purpose of this exercise is to show how it is done. Both operators need to implement GTSM on the peering link, which means coordination is required.
We are now going to implement GTSM on the EBGP session with the upstream provider, and on the private peering link between the adjacent groups. We won’t implement it with the IXP peers.
For the upstream provider, coordinate with the lab instructors using Discord regarding enabling GTSM on the IPv4 and IPv6 EBGP peerings with the transit router.
Here is an example for the Border Router, peering with the upstream provider:
router bgp X0
!
address-family ipv4
neighbor <ipv4-ptp> ttl-security hops 1
!
address-family ipv6
neighbor <ipv6-ptp> ttl-security hops 1
!Likewise, when you are ready to set up with your private peer, coordinate with them through Discord, so you can implement the GTSM configuration at the same time on both ends of the session. The configuration needed on the Peering Router has the same construction as in the example above.
Once you have configured GTSM on these two peerings, it is time to do some testing. What does the command:
show ip bgp neigh <ipv4-ptp>on the border router show you now?
Verify that you see, in the detailed output from the command, something like this1:
Mininum incoming TTL 254, Outgoing TTL 255
Local host: 100.121.0.1, Local port: 41103
Foreign host: 100.121.0.2, Foreign port: 179 The lab instructors already use GTSM between the two Transit Routers, and the output above is from the BGP session between the two. Your’s should look very similar.
Also verify you see the same on the EBGP session with your private peer.
GTSM is now configured and operational.
Note: Cisco IOS uses hops 1 in its configuration construct - this may be counterintuitive given we are setting TTL to 255, but it seems the Cisco developers are focusing on describing what is actually allowed. Other vendor implementations have configuration letting operators set the TTL value - care is needed here!
This section is all about verifying the behaviour of propagating BGP communities within and between Autonomous Systems.
It is generally accepted that all IBGP neighbours must propagate all communities across the internal network. Which means that the IBGP configuration must include any commands to send communities if it is not the operating system default. This ensures that any communities set by the network operator are visible and propagate around their infrastructure. Failing to propagate communities which have been set for a particular purpose could result in route leaks or some unusual behaviour in the network.
The situation is quite different for EBGP sessions. Communities are recognised as a method of implementing local policy. Local can mean two things:
Local as in within the autonomous system
Local as in between adjacent autonomous systems
It is rarely desirable to propagate communities beyond adjacent autonomous systems, and definitely not desirable to propagate internal communities outside the local network or allow neighbouring networks to send your internal communities to you.
The lab exercise is more of a sanity check of our current existing configuration. In the earlier IBGP lab we should have set up neighbor <address> send-community on our ibgp peer-groups. All groups should now check that those peer-groups have the send-community set on them.
You should see this on the Border, Peering, and Access routers:
router bgp X0
!
address-family ipv4
neighbor ibgp-rr send-community
!
address-family ipv6
neighbor ibgpv6-rr send-community
!And on the Core router, you should see:
router bgp X0
!
address-family ipv4
neighbor ibgp-full send-community
neighbor ibgp-partial send-community
!
address-family ipv6
neighbor ibgpv6-full send-community
neighbor ibgpv6-partial send-community
!If any send-community option is missing from the peer-groups, please make sure they are in place now.
Also, do check that Cisco IOS configuration uses the “new format” option - this refers to the format used in RFC1998, rather than the plain 32-bit integer as used in the specification in RFC1997. Check that this command is in the configuration:
ip bgp-community new-formatThis will ensure that communities are displayed in the 16-bit:16-bit format which is more human readable.
For this step, please check that there is not any send-community configuration on the EBGP peerings - we will turn this feature on in future lab exercises only as required.
The final exercise in this lab is to include a command/configuration to drop any prefixes originated from private AS numbers used within the network.
Many network operators will use private AS numbers internally in their networks, either for test labs, individual offices, or customer dual-homing, or other features where AS numbers are needed, but do not need to be announced globally. As per Section 10 of RFC1930, private AS numbers must not be announced to the global Internet.
However, what happens if an operator needs to announce a prefix originated by one of these private ASes out to the public Internet. The original method would be that the operator originates the prefix from its own public autonomous system, overriding the origination done by the connected private AS. This works up to a point, but causes problems if the network using the private AS disconnects from its upstream - the upstream will still originate the prefix. The vendors introduce a feature to remove the private ASN from the AS-PATH - this gave the appearance of the prefix being originated from the upstream public ASN instead. So rather than:
100.64.0.0/16 100 200 64512appearing in the global Internet (illegal AS announcement), the actual prefix announcement would be:
100.64.0.0/16 100 200RFC6996 extended the range of private AS numbers to include AS numbers from 4,200,000,000 to 4,294,967,294 - these are useful for larger networks which have used up the original 1023 reserved by RFC1930.
We now will set up BGP on the Customer Router. Rather than using the IPv4 and IPv6 space assigned to the customer for testing purposes earlier on in the workshop, we will use a separate address block.
The new address block is listed in the Address Plan under the Customer Provider Independent section. Refer to the address plan, and make a note of your IPv4 and IPv6 address blocks.
Next, we create the process using the private AS number 64512 and originate the address block in question. Here is an example configuration:
router bgp 64512
bgp log-neighbor-changes
bgp deterministic-med
no bgp default ipv4-unicast
!
address-family ipv4
distance bgp 200 200 200
network 100.68.10X.0 mask 255.255.255.0
!
address-family ipv6
distance bgp 200 200 200
network 2001:DB8:10X::/48
!
ip route 100.68.10X.0 255.255.255.0 null0
ipv6 route 2001:DB8:10X::/48 null0
!Next we need to set up eBGP with the Access Router. First we create the prefix-lists needed, for inbound and outbound filtering:
ip prefix-list CustX-out permit 100.68.10X.0/24
!
ip prefix-list default permit 0.0.0.0/0Do the same for IPv6:
ipv6 prefix-list CustX-v6out permit 2001:DB8:10X::/48
!
ipv6 prefix-list v6default permit ::/0and then applying the configuration to the eBGP neighbour:
router bgp 64512
!
address-family ipv4
neighbor 100.68.X.34 remote-as X0
neighbor 100.68.X.34 description eBGP with ASX0
neighbor 100.68.X.34 prefix-list CustX-out out
neighbor 100.68.X.34 prefix-list default in
!
address-family ipv6
neighbor 2001:DB8:X:31:: remote-as X0
neighbor 2001:DB8:X:31:: description eBGP with ASX0
neighbor 2001:DB8:X:31:: prefix-list CustX-v6out out
neighbor 2001:DB8:X:31:: prefix-list v6default in
!
We now need to set up the matching configuration on the Access Router in each group’s AS. Again we need to set up prefix-lists before we set up the eBGP session - here is an example of the IPv4 prefix-list for all groups:
ip prefix-list CustX-in permit 100.68.10X.0/24
!
ip prefix-list default permit 0.0.0.0/0
!And the IPv6 prefix-list for all groups:
ipv6 prefix-list CustX-v6in permit 2001:DB8:10X::/48
!
ipv6 prefix-list v6default permit ::/0
!We now set up the eBGP session on the Access router:
router bgp X0
!
address-family ipv4
neighbor 100.68.X.35 remote-as 64512
neighbor 100.68.X.35 description eBGP with Customer
neighbor 100.68.X.35 prefix-list CustX-in in
neighbor 100.68.X.35 prefix-list default out
neighbor 100.68.X.35 default-originate
!
address-family ipv6
neighbor 2001:DB8:X:31::1 remote-as 64512
neighbor 2001:DB8:X:31::1 description eBGP with Customer
neighbor 2001:DB8:X:31::1 prefix-list CustX-v6in in
neighbor 2001:DB8:X:31::1 prefix-list v6default out
neighbor 2001:DB8:X:31::1 default-originate
!Note the default-originate on the eBGP session - we are announcing the default route to our customer as they do not need the full BGP table or any other routes apart from default.
Because we are now getting a customer originated route from a provider independent block, we need to tag it with the correct community. Refer to the previous community lab - we noted that Customer independent addresses (which this one) go into community AS:1005. To do this, we create a route-map, like this:
route-map set-pi-community permit 5
description Set community on Provider Independent prefix
set community X0:1005
!and then we add it to the BGP configuration:
router bgp X0
!
address-family ipv4
neighbor 100.68.X.35 route-map set-pi-community in
!
address-family ipv6
neighbor 2001:DB8:X:31::1 route-map set-pi-community in
!If the peering is already up from the previous step, you will need to do a route-refresh so that the community becomes attached to the prefix being announced.
Once the Access Router is configured, we can now go back to the Customer Router and remove the static default routes for IPv4 and IPv6:
no ip route 0.0.0.0 0.0.0.0 100.68.X.34
no ipv6 route ::/0 2001:DB8:X:31::Confirm that connectivity still works, as you did earlier on in the eBGP lab - routing between the Customer Router and its upstream should now be relying on BGP.
Now check on the Core Router for the prefix announcements originated by the Customer Router, and being transited by the Access Router. Use the sh ip bgp and sh bgp ipv6 unicast commands to find out the state of the IPv4 and IPv6 BGP tables. What do you see?
You should see that the 100.68.10X.0/24 and 2001:DB8:10X::/48 prefixes are being originated from AS 64512. Here is an example from the Border Router in Group 1 from a previous version of this lab:
B1#show bgp ipv4 unicast 100.68.101.0
BGP routing table entry for 100.68.101.0/24, version 15
BGP Bestpath: deterministic-med
Paths: (1 available, best #1, table default)
Advertised to update-groups:
1
Refresh Epoch 1
64512
100.68.1.4 (metric 4) from 100.68.1.2 (100.68.1.2)
Origin IGP, metric 0, localpref 100, valid, internal, best
Community: 10:1005
Originator: 100.68.1.4, Cluster list: 100.68.1.2
rx pathid: 0, tx pathid: 0x0Compare the above with what you see. Also check the IPv6 status. You should see an output similar to the following:
B1#show bgp ipv6 unicast 2001:DB8:101::/48
BGP routing table entry for 2001:DB8:101::/48, version 15
BGP Bestpath: deterministic-med
Paths: (1 available, best #1, table default)
Advertised to update-groups:
1
Refresh Epoch 1
64512
2001:DB8:1::4 (metric 4) from 2001:DB8:1::2 (100.68.1.2)
Origin IGP, metric 0, localpref 100, valid, internal, best
Community: 10:1005
Originator: 100.68.1.4, Cluster list: 100.68.1.2
rx pathid: 0, tx pathid: 0x0Are you able to explain everything you see in the show bgp outputs above?
Ask your peers and upstreams if they see any prefix announcements coming from you with AS64512 as the origin AS.
We cannot allow this private AS to leak out to the Internet or to private peers, so we need to fix our EBGP sessions.
We will now modify our EBGP peering sessions to strip out any private AS number which might appear as the origin AS in any announcements we make to our neighbours. The Cisco IOS command to do this is remove-private-as.
Here is an example for the Border Router, peering with the upstream provider:
router bgp X0
!
address-family ipv4
neighbor <ipv4-ptp> remove-private-as
!
address-family ipv6
neighbor <ipv6-ptp> remove-private-as
!which will remove the private AS from any prefixes we originate in internal autonomous networks. Remember to apply a route-refresh once you have added this configuration.
Don’t forget to apply the remove-private-AS configuration to the eBGP configurations on the Peering Router as well! This is why the BGP Best Practices presentation mentions and recommends the use of standard templates for IBGP and EBGP configurations.
Also, don’t forget to update your inbound prefix filters on the Peering Router to allow your peers to send you these new prefixes. This means updating the prefix-lists IXP-RS and IXP-v6RS to allow these extra prefixes in.
You also need to update the inbound prefix-list ASY0-block for the private peering between your group and the adjacent group, so it would end up looking like this:
ip prefix-list ASY0-block permit 100.68.Y.0/24
ip prefix-list ASY0-block permit 100.68.10Y.0/24and:
ipv6 prefix-list ASY0-v6block permit 2001:DB8:Y::/48
ipv6 prefix-list ASY0-v6block permit 2001:DB8:10Y::/48Once you have updated the Peering Router EBGP configuration, don’t forget the route-refresh inbound so that the new prefixes are allowed through the new filters.
Once we have added the remove-private-as configuration on all our EBGP sessions, we need to do some testing to show that this works.
What do you see now?
Do your neighbours see any prefixes coming from you which are originated from private ASes?
Note 1: Cisco’s remove-private-as command only applies to AS numbers from 64512 to 65534. For the remaining private AS numbers (4200000000 and above) you will need to proxy the prefix announcement from the Access Router. Do you know how to do this2?
Note 2: If you are using documentation AS numbers (64496 to 64511 and 65536 to 65551) for internal use, you will also need to proxy the prefix announcement from the Access Router.
This series of exercises has shown how to lock down the EBGP configuration to protect peering sessions from abuse or mistakes by peers or other entities across the Internet. These 5 labs introduced techniques which are considered by many to be operational best practices for BGP in today’s Internet.